
Comienzo con una confesión: no soy músico ni productor de música, aunque de vez en cuando, en noches tristes, agarro la guitarrita. A veces, hasta me pongo a grabar “covers” que no llegarían a segunda ronda de American Idol. Soy amante de la música, es cierto, aunque admito que la cantidad de material en mi colección, si la ordenáramos por fecha, decaería exponencialmente a partir del año 2000. De otra parte, llevo los últimos 7 años de mi vida estudiando la voz humana desde el punto de vista computacional. Esto comenzó como un interés por modificar voces con el fin de simular o fingir identidades. Inicialmente, me interesaba desarrollar un algoritmo que pudiese hacer que cualquiera sonara (más o menos) como sus cantantes favoritos. Varias circunstancias (mayormente, la disponibilidad de fondos para investigación) me llevaron a concentrarme en otro tema, relacionado pero menos “sexy”.
En fin, que me ha tocado analizar más estimados de ondas glotales de lo que consideraría saludable, pero esto me ha llevado a comprender bastante bien el mecanismo de producción de la voz humana y las limitaciones del procesamiento algorítmico de su señal capturada.
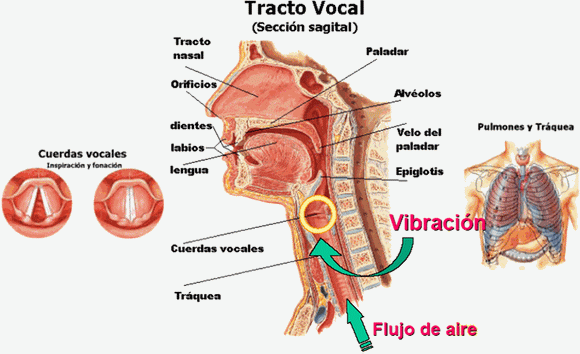
Sucede que la onda glotal tiene mucho que ver con las cualidades de la voz, como lo son el “timbre” y la “textura”, entre tantos adjetivos que intentan calificar lo que percibe el oído. Quizás la cualidad más fácil de medir y manipular de la onda glotal en la voz cantada es su periodo de oscilación el cual (casi siempre) determina el tono musical (“pitch”) percibido por el oyente. Sin que se duerma nadie, aclaro brevemente que la glotis es el espacio entre las cuerdas vocales por donde pasa el aire que proviene de los pulmones y entra al tracto vocal. Al separarse y juntarse las cuerdas vocales, crece y disminuye el tamaño del hueco por donde puede pasar el aire. El resultado de esta oscilación es una onda acústica que es filtrada por las estructuras del tracto vocal. Dentro del tracto vocal se crea una serie de resonancias, conocidas como formantes, que dependen de la posición de la lengua, mandíbula, labios, etc. Estas formantes influyen en la percepción cualitativa e identitaria de la voz, pero a su vez son esenciales para que el aparato auditivo reconozca los fonemas, particularmente las vocales.
Acudo a este trasfondo sobre la fisiología de la voz pues quisiera reflexionar brevemente sobre el uso de efectos digitales en la voz cantada, particularmente sobre la corrección de tono (pitch). Popularmente conocida como AutoTune, que no es más que una implementación particular y propietaria del proceso, la corrección de tono busca modificar la señal de la voz para que parezca que el cantante produjo una nota musical distinta a la que posiblemente produjo. Es decir, intenta modificar la señal para que se escuche como si las cuerdas vocales hubiesen vibrado a la frecuencia “correcta”.
Existen diversas maneras de modificar el tono musical de la voz [1-2], pero algunas de las ideas fundamentales salieron del trabajo de Homer Dudley quien desarrolló el “vocoder” durante la década del 1930. Originalmente, el propósito primario del aparato no tenía que ver directamente con música, era si acaso un asunto de comunicación telefónica y militar. Tras haberse adoptado masivamente la telefonía, surgió un gran interés por lograr transmitir la mayor cantidad de llamadas utilizando la menor cantidad de infraestructura física. Más tarde, la Segunda Guerra Mundial desataría esfuerzos de inteligencia dirigidos a desarrollar mejores sistemas de comunicación criptográfica. Dudley observó que si se dividía la voz humana en varias bandas de frecuencia (aproximadamente 10 bandas), se abría la posibilidad de codificar la energía en cada banda con una señal de baja frecuencia, y por ende transmisible por un conducto físico de menor capacidad. El aparato de Dudley era completamente analógico, y la calidad de la voz codificada, si bien impresionante para la época, no era del todo placentera.

Aunque la telefonía comercial no adoptó el vocoder inicialmente, la idea detrás del aparato —es decir, su algoritmo— inspiraría los sistemas digitales de compresión de voz que se usan actualmente, particularmente en la telefonía celular y la transmisión de voz a través del Internet. El vocoder de Dudley se utilizó durante la Segunda Guerra Mundial como parte de un sistema para la transmisión cifrada (encriptada) de la voz, por el cual conversaron Roosevelt y Churchill. Para esta aplicación la estética de la transmisión no importaba tanto, no era esencial para administrar la guerra.
La operación del vocoder de Dudley se basaba en la observación de que las formantes (frecuencias resonantes en el tracto vocal relacionadas a la pronunciación de los fonemas) varían lentamente (10 fonemas por segundo, más o menos) con respecto al tono de la voz, que puede ser de 100 a 200 hercios, para voz hablada. A su vez, el tono de la voz tiende a seguir un contorno más o menos continuo, sin cambios abruptos. Esto quiere decir que si se logra detectar las formantes que se producen en el tracto vocal, y a su vez se logra medir la frecuencia de oscilación de las cuerdas vocales, podrían transmitirse únicamente estos parámetros de lenta variación, que como hemos mencionado ocupan menor capacidad de transmisión debido a su baja frecuencia. De esta manera, el aparato receptor sería capaz de reconstruir una aproximación razonable de la voz (síntesis) utilizando los mismos parámetros.
En teoría, el haber separado las resonancias del tracto vocal de lo que sucede en la glotis permitiría modificar un componente de la voz independientemente del otro. En el contexto de la voz cantada, se abriría la posibilidad de modificar el tono musical sin alterar las formantes. Es decir, sería ahora posible alterar la nota que se está cantando, a la vez que se conservan otras cualidades perceptivas de la voz humana, tales como el timbre, la identidad del cantante y el fonema (la vocal). Esto es lo que tratan de hacer, de una manera u otra, los modificadores de tono que han ido invadiendo la producción musical. Su popularidad reciente, más allá de modas y gustos, tiene que ver con la habilidad de aplicar el efecto de forma automática y en tiempo real.
Aunque la rusticidad del efecto se utiliza para generar voces que suenan intencionalmente intervenidas, trayendo a la memoria los efectos de síntesis cruzada de los años ‘70 y ‘80 (que son los que se asocian popularmente con el término “vocoder”), en las instancias donde la meta es corregir errores de afinación sin que se perciban “efectos secundarios”, otras limitaciones exigen ser atendidas.
Comenzamos con que la manera de vibración de las cuerdas vocales, y no solamente su periodo de oscilación, varía significativamente con respecto a la nota musical. Ya de entrada esto implica que un cambio en tono verdadero (producido por el cantante) estaría acompañado por un cambio timbral. Esta relación entre tono y timbre suele variar entre individuos y es difícil de modelar. Aún si se modelara, se tendría que enfrentar el problema de que la señal acústica de la voz es una mezcla (una convolución, aproximadamente) de sus componentes bucales y glotales, de tal forma que la separación de estos componentes con algún nivel de exactitud resulta sumamente difícil. Al no poder separarlos adecuadamente, la tarea de determinar cuáles aspectos de la señal debemos manipular y cuáles debemos preservar se complica.

A esto habría que añadir el reto de que las cuerdas vocales no oscilan a una frecuencia completamente estable, incluso durante una nota sostenida. Existen, por ejemplo, niveles y formas de vibrato, donde el cantante varía intencionalmente la frecuencia de oscilación para “pasearse” por encima y por debajo de la nota que se supone esté produciendo —sí, tenemos dos sistemas de oscilación a distintas escalas de tiempo. Aunque hay maneras de simular este vibrato artístico —de hecho, el vocoder de Dudley lo podía hacer—, circunscribirse a una curva predeterminada ya puede resultar en una voz de imposible y desconcertante “perfección”.
Más allá de los asuntos puramente técnicos, la manera en que un cantante acierta o desacierta una nota es parte de su expresión emotiva, de su encanto, de su habilidad para cautivar a las masas. Cuando removemos esa dimensión lírica, por aquello de erradicar la disonancia, estamos lobotomizando la voz. Esto no es noticia. Muchos, dentro y fuera de la industria, se han quejado de la creciente homogeneización de las voces en ciertos géneros musicales. Bastaría con escuchar un “éxito” reciente de tres cantantes distintxs de música Pop. A pesar de la impresionante capacidad que tenemos los humanos para identificar voces, cada vez es más difícil descifrar cuál de todxs está cantando.
En la irónica búsqueda por la perfección dentro de un género musical originalmente viabilizado por la tecnología de amplificación electrónica, que permite que cantantes con poco entrenamiento vocal se escuchen por encima de los instrumentos, algún productor olvidó la belleza contenida en los desfases e inconsistencias de la voz. Igual se cansó de tener que obtener quinientas muestras para sacar algo soportable de un talento escogido por su habilidad para montar un espectáculo visual antes que por el carácter y la singularidad de su voz. Así terminamos con las voces serializadas que hoy invaden la radio y los espacios públicos con su banal y aguda inexpresividad. Perversamente, el Autotune ha consumado el propósito original del vocoder: transmitir a la audiencia la cantidad mínima aceptable de información.
Notas:
[1] Gold, Morgan and Ellis, Speech and Audio Signal Processing, 2nd Ed., 2011.
[2] Udo Zölzer (Editor), DAFX: Digital Audio Effects, 2nd Ed., 2011.
Lista de imágenes:
1. Franz Falckenhaus, "Lobotomy", 2011.
2. Diagrama del tracto vocal.
3. Homer Dudley, creador del vocoder.
4. Franz Falckenhaus, "Himself", 2008.
